

Operating Systems are the single most important piece of software on any computer system. All computer systems must have an operating system in order to work, whether you notice it or not! Any OS is an incredibly complex and intricate piece of software, written by some of the best programmers to have ever touched a computer.
The operating system will dictate how you use a computer system, what it is capable of, how easy to use it is and what hardware you can use. In short, if you can do something on a computer, it is because of the operating system doing a lot of complicated work in the background.
In this section (click to jump)
- What is an Operating System?
- Memory Management and Multitasking
- Peripheral Management and Drivers
- User Management
- File management
What is an Operating System?
The short answer is software. Operating Systems are nothing more than software – a set of instructions designed to perform a specific task. The long answer is complicated.
Any operating system must perform a set of tasks on a machine:
- Recognise all hardware
- Manage communication between all hardware devices (make them “work”)
- Manage all storage and memory
- Manage what the CPU is doing at all times
- Provide a platform on which other software (apps) can run on
- Provide a method for the user to interact with the system – the interface
That’s a lot of stuff. Fortunately, for our GCSE we can condense that down into the following short definition:
An operating system is software which controls and manages ALL hardware, software and resources in a computer system. It provides a platform on which software can be installed and used.
There are lots of operating systems and you’ve probably used or heard of all the most common:
 |  |
 |  |
In our definition we stated that an operating system must control all hardware and provide a platform for software to run on. These functions are provided by something called a Kernel.
The part users interact with is called the User Interface. The user interface is the most recognisable part of any system because it is quite literally the thing that you see, it is the “face” of the system.
Kernel
To all intents and purposes, the Kernel is the operating system. The Kernel is still software, but it is responsible for all of the hardware and software in the computer system on which it runs. Users never interact directly with the Kernel, we have interfaces to abstract this complexity away from us. Software, however, relies heavily on the Kernel for everything it does from loading up, allocating memory for the program to run in, to saving and loading of files.
When we say that an Operating System “provides a platform for software to run on” it is the Kernel that provides this platform, but what does this mean?
On one hand, the Kernel is responsible for organising what the CPU, RAM and other hardware are doing, when they do it and how long for. On the other hand, the Kernel is responsible for providing a vast array of common system functions that software will need in order to function.
If you think about it, there are lots of things that nearly all applications will need to do. For example:
- Mouse movement, knowing the position of the mouse and reading any button presses
- Reading the keyboard – translating and storing the electronic signals sent by the keyboard controller to the system
- Reading and writing data to storage
- Printing
- Reading data from input devices
- Providing output, such as an image on a display
Absolutely none of this can happen without software. Anything which happens on a computer system is happening as a result of code being executed. Even the simplest of tasks – reading a key stroke from the keyboard and displaying the resulting letter on screen is the result of hundreds of instructions being executed from code written to handle the keyboard and screen.
This, then, is a mammoth task. In a computer system without an operating system, a programmer must write all of this code themselves. This may be acceptable in very small, specific embedded / micro controller systems, but for anything larger it would quickly become an overwhelmingly complex task.
The Kernel provides all of these services to applications / software. Therefore, when an application needs to save a file, the developers do not need to write this code – they simply pass the relevant data over to the Kernel and it sorts the difficult bits out and stores the data on whichever device was specified.
This has huge benefits for developers – their programs are smaller, there is less work to do and Kernel functions are super robust and well tested which effectively means (as near as possible) they just don’t go wrong – the Kernel can be relied upon to be as close to 100% reliable as is possible.
Kernel functions are basically standard methods of doing something. If you want to know the last position of the mouse, call the mouse position function. If you want to print a document, call the print function – but your program must provide data in the very specific form that the operating system expects. These standards and expectations are laid out in what is called an API (Application Interface) and will be well documented by Microsoft, Apple, or whomever wrote the Operating System.
This standardisation also explains how drivers work and why they are necessary. We discuss this in more detail later, but to summarise here – because the operating system works in a generic, set way, drivers are required to translate between these generic operations and the specific ways in which hardware works. Drivers enable operating systems to interact with new hardware that could never have been imagined when the operating system was written, they enable hardware manufacturers to keep their specific methods a trade secret and to add new features to hardware whenever necessary.
Some examples of things the Kernel is responsible for are below:
- Loading programs when requested by the user
- Loading and saving files
- Deciding which program should be running on the CPU at any given time
- Organising and allocating memory space to programs
- Organising and allocating storage space
- Communicating with all hardware devices
- Managing all users of the system
There are many, many more things the kernel is responsible for – but this list will suffice at GCSE to give us an idea of what is going on under the surface in a computer system.
User Interfaces
User interfaces are an “abstraction layer.” This is a complicated way of saying they hide a lot of complexity and allow users to simply and conveniently interact with a system.
An interface is the point at which users interact with a computer system. It will consist of both hardware input and output devices and software.
Interfaces come in many forms, but two are most prevalant in computing:
- Graphical or Graphical User Interface (GUI)
- Command Line (CLI)
Both perform the exact same task – allowing users to control a system, load and use programs. However, they offer vastly different user experiences and require different levels of knowledge to use.
Command Line Interfaces (CLI)
A CLI allows interactions with a computer system through:
- A keyboard – to type and enter commands into the system
- Command words – special key words assigned to specific tasks that the system understands
It would be easy to jump to the conclusion that command based interfaces are “old fashioned” and are no longer used. Indeed, you may never have the need to use one in your life, but they are actually still widely used and incredibly powerful methods of controlling an operating system.
Commands are typed in using a keyboard and appear on the command line. An example is shown below:
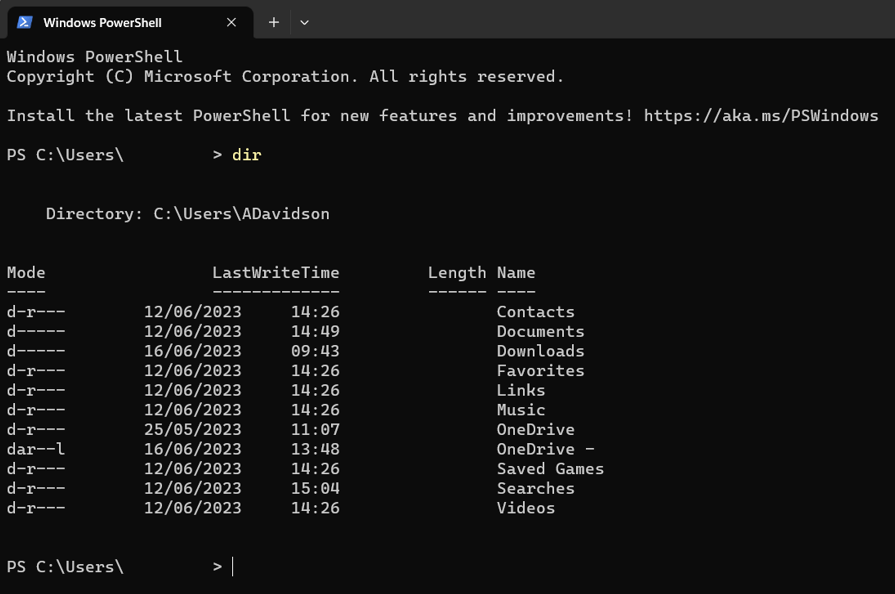
The command line is simply a prompt for the user to type something. In the picture above you can see the command “DIR” has been typed in, which stands for “directory” – another word for folder. When the enter key was pressed, the command line executed the command and displayed the contents of the current folder or directory.
All modern operating systems actually come with an optional command line interface all built in. Linux and MacOS have “terminal” whereas Windows offers “Powershell.” They all allow complete control over the system or access to features that may not be possible to use under their respective graphical user interfaces.
Commands are short, simple and usually descriptive. Some examples of Linux commands are:
- LS – List Structure – shows the contents of a directory
- RM – Remove – deletes a file or directory
- CP – Copy
- CHMOD – Change Mode – changes access rights to a file, folder or executable
- SUDO – Super User Do – Perform an action as a super user (administrator)
- TOP – Table of Processes – Shows what is running on the computer at any given time
Some commands cannot be entered on their own and require extra data in order to carry out their task. This extra data is called “parameters.” Furthermore, you may want to modify how a command is carried out, which can be done using switches.
For example, to delete a file, you need to give the name of that file:
RM myfiletodelete.txtBut if you wanted to delete everything in a folder or directory, you’d need to use the -R switch to tell it to “recursively” delete things. Recursive mode means the delete command looks in every sub folder and deletes the contents therein.
RM -R myfoldertodeleteThere is no help given to the user in a command line interface. To interact via command line, the user must be aware of all the commands that they may need in order to do their work. If you make a spelling mistake, the command line will simply return a rather unhelpful error message. This is obviously a steep learning curve, but once these commands have been learned users are able to interact with the computer system in an incredibly efficient and powerful manner.

Command lines offer one feature that no other interface does – scripting. This is an extraordinarily powerful tool which can be used to automate complex tasks. A script is effectively a computer program – it contains a list of commands which are executed by the command line. Any command that can be typed in to the command line can be used in a script.
Scripts are used to perform repetitive tasks such as renaming a group of files, creating hundreds of new user accounts or performing the backup of files at a given time. The possibilities of script files are almost endless and they have the potential to save users hours and hours of work.
The example script below would take a folder of images and create thumbnails of those images in a new folder. Imagine if the folder contained 1000 images, this would take someone using a GUI many, many hours to complete. Using a script, the task can be run in the background and is likely to complete in seconds.
#!/bin/bash
# This makes a directory containing thumnails of all the jpegs in the current dir.
mkdir thumbnails
cp *.jpg thumbnails
cd thumbnails
mogrify -resize 400x300 *.jpgTo summarise, a command line interface:
- Is entirely text based, no graphics are used, no mouse control
- All control of the computer is through the entry of short text based commands entered on a keyboard
- Commands usually describe the job they perform or are abbreviations – CP = Copy
The advantages of a CLI are:
- They are not resource intensive – CLI’s do not require large amounts of CPU power, time nor RAM space
- They are extremely powerful once users know the commands
- They can be used to create and run scripts which automate complex or time consuming tasks
The disadvantages of a CLI are:
- They are confusing for new users as they are not intuitive
- Mistakes result in error messages which can be difficult to understand
Graphical User Interfaces (GUI)
Most people will think that the Graphical User Interface is the operating system. This is a common and understandable misconception because GUI’s are the standard type of computer interface and it so successfully hides away all of the underlying complexity of the operating system that it would be reasonable to assume that the GUI is the system itself.
A GUI will consist of four main components, carrying the acronym WIMP:
- Windows – the ability to compartmentalise a program in its own container which can be moved, resized or minimised (hidden) on request.
- Icons – graphical representations of files, folders and programs to make it easy to know what things are just by looking at them
- Menus – to group together common options in a place which is convenient and easy to find.
- Pointer – either a mouse cursor on screen or your fingers, something which can be used to quite literally point at what you want to use, select or interact with.


GUI’s are far more intuitive than command line interfaces. Users can usually work out how to use and operate a system simply by looking at the screen and working out what icons mean, using visual and audio cues to know when they are doing something right or wrong.
The invention of touch interfaces has been something of a revolution in operating system interfaces as it finally allowed people to use their instincts and intuition to simply touch the things they want. It is very natural to resize an image, for example, by pinching and squeezing it rather than having to move a mouse pointer to the edge and drag it around.
For all of their advantages, GUI’s do have a couple of downsides, primarily resource usage. A graphical interface, by definition, requires graphics processing power and memory in order to work. The more complex a GUI and the more effects it uses then the more processing power that will be required to drive it. This can particularly be an issue for devices that rely on battery power to function. Fortunately, modern CPU and GPU design has advanced to the point where displaying an interface requires very little processing and battery power compared to devices powered by older hardware.
The second disadvantage of GUI’s is that there are some tasks which cannot be simply, conveniently carried out. As we learned previously, CLI’s have the ability to execute commands in the form of scripts – effectively computer programs which perform tasks for the user. As GUI’s require users to interact with specific elements such as clicking on buttons, selecting tick boxes or options from a drop down menu, automating these actions is rather difficult. It is for this reason that nearly all modern operating systems which use a GUI also include powerful CLI windows called Shells or Terminals which can be used in these circumstances.
To summarise, a graphical user interface:
- Is based on four components – Windows, Icons, Menus and a Pointer
- Provides an intuitive way in which users can interact with a computer
- Used by nearly all modern operating systems
The advantages of a GUI are:
- They are intuitive – users can figure out how to complete tasks without training or instruction
- Allow users to multitask due to applications being in windows – can easily switch tasks or have multiple windows on screen at once.
The disadvantages of a CLI are:
- They require more resources in terms of processing power, GPU power and memory compared to CLI’s
- Cannot be used to easily perform some repetitive tasks which are better suited to CLI or script based environments.
Memory Management and Multitasking
The operating system is responsible for managing all hardware and software in a computer system. This is a mammoth task, to say the least. Two of the most essential resources in a computer system are the CPU and RAM. These two components together are effectively all you need to perform computational tasks (if you ignore the need to actually see the results…)
Neither the CPU nor RAM are capable of making any decisions. The CPU does not decide which task to complete next, the RAM does not decide which programs to load into itself ready for execution. Both of these roles are carried out by the operating system.
Managing RAM
As you well know by now, all programs must be first loaded into RAM before they are executed by the CPU. The purpose of loading programs into RAM is to speed up execution as it has much, much faster read and write speeds compared to secondary storage devices.
RAM is nothing more than a huge storage space for binary data. You can imagine it as a large, empty room – there have been no decisions made about how to organise that room and the possibilities are almost endless. As you open programs and they are copied in to RAM the OS will decide where these programs go, how best to organise RAM so the available space is used efficiently.
The OS and memory controller in tandem perform quite an incredible task. A programmer has no idea where their program will ever be placed in memory. It could (and will) be placed in a different location every time it is used. To a program, it always exists in the same place and will point to memory addresses relative to itself. The OS takes care of this problem and translates between the addresses the program thinks it needs to the addresses it actually needs.
Most operating systems split memory into equally sized chunks called “pages.” Programs are then allocated to these pages and the OS keeps track of where each one is. If a program needs more space, it can be allocated more pages. Magically, a program can have its pages moved around by the operating system (remember virtual memory?) and continue working without noticing a thing has changed.
This segmenting of memory has a few really useful trade offs – security and multitasking. The operating system will not allow a program to access memory outside of its allocated range. This stops, for example, malicious code in one program looking in the memory space of your web browser in order to steal your passwords and other data.
By managing memory, the OS can allow more than one program to be loaded in to memory at once. This is called “multi-programming” and if it sounds obvious to you, it is worth reminding you that not too far back in computing history, programs used to assume control of all memory space when they were opened. There was no such thing as having two programs open at once and switching between them!
Multi-programming is a fine idea, but this only means more than one program is loaded into memory at once, it doesn’t mean you can use them simultaneously. To multitask, the OS must perform some more feats of genius which we will look at in the next section.
Memory management – an overview
- Memory management is an essential feature of any operating system. If you imagine RAM as a huge container – the OS has to decide where to put things and how this massive space should be organised.
- This is because programs are not “aware” of each other and this could easily lead to programs over writing each other, corrupting other data or serious security issues.
- The OS, therefore, splits RAM up and as programs are loaded it organises them in to pages of RAM.
- Memory management splits programs up and keeps them from interacting with other programs unless necessary
- This means you can run/open more than one program at once! This is called “multi-programming”
- When a program closes, the OS will free up the space that program was using so that other programs can then use that space.
- Memory management also looks after Virtual Memory (click to read about that) and manages the movement of data to and from virtual memory to allow more programs to be opened than we actually have physical RAM to store them in.
Multitasking

Conceptually, multitasking is performing two or more tasks at the exact same time. In computing, even with modern processors, this gives us something of a problem. It may be easiest to start at the beginning with a definition and what this means in a single core, single CPU environment.
Multitasking is when an operating system allows two or more programs to be running simultaneously.
These programs may be visually side by side on screen and quite apparently both doing things at the same time, or it may be that one program has the attention of the user whilst other tasks run in the background such as a virus scan or a file being downloaded in a web browser.
Why might this be a problem for a computer? After all, every computer you have ever used has allowed you to do more than one thing at a time – such as writing in a Word document whilst music plays in the background from a YouTube video or Spotify playlist. It turns out that this has not always been possible.
Multitasking has been an almost essential component of operating systems and computers since around 1990. Early attempts at multitasking environments were not the seamless experience that you are so used to now. Windows 3 and early versions of Mac System had rudimentary multitasking capabilities but they were not without their faults. Linux and Unix have always been multi-user and multi-tasking operating systems. As computing developed it became blindingly obvious that there was a real need to be able to run programs side by side or at least to be able to switch between them and share data.
The problem is that, until around 2004, the computer sat on everyones desk was a single core, single CPU machine. Remember back to your lessons on the CPU and the fetch, decode, execute cycle and you should see where this is going – a single CPU may only run one program at any one time. It cannot fetch, decode and execute instructions for two programs at once, at the same time!
Yet, in 1995 the world was treated to Windows 95 and one of the biggest selling points was “seamless multitasking.” How was this possible on a Pentium 133mhz CPU? The answer is that technically, it wasn’t possible! Were we being lied to?! Is it tin foil hat time?

No, not quite.
Multitasking actually contributes one reason why it is necessary to have such high CPU clock speeds. In the most simplified terms, when you ask an operating system to run two or more programs at once it schedules them so that every second, the CPU swaps between tasks carrying out a little bit of each at a time. It does this so quickly that to the user, there is no delay to be seen and it is not noticed.
By doing this swapping between tasks, the operating system and CPU together give the effective illusion of more than one thing happening at once. If one task is particularly more demanding compared to another then the operating system can schedule more time for that task than others – this is called prioritisation and all tasks carry a priority. We are massively simplifying how this happens at GCSE level and there are lots of other software and hardware tricks at play here to keep everything appearing to run smoothly.
Multitasking in this way has its limits, however. The more tasks you demand of your computer, the less time can be spent on each one. There is a point at which you demand so much of the CPU that it cannot effectively process each program in time before moving on to the next. This is seen in delays or the computer appearing to “freeze.” You will have surely experienced when typing on a computer that at times it can appear to have stopped working then suddenly all of your text appears at once on the screen – this is a sure sign that another task of a higher priority demanded so much CPU time that the operating system decided to delay servicing your keyboard request.
The advent of multi-core CPU’s went a long way to provide an improvement in multitasking speeds and capabilities. Obviously, if you have a dual core CPU then you can quite genuinely run two tasks at the exact same time – there is no illusion or trickery here, you really are getting true multitasking happening. The more cores you have, the more “genuine” multitasking you can have.
However, this ignores many clever things that go on behind the scenes, such as programs themselves being split into “threads” which can be run in parallel and effectively multitask within themselves to speed up execution. Fortunately for you, this is not a GCSE topic!
Multitasking, a summary:
- A CPU can only perform one task at any one time. A CPU may have many cores and each core can also only perform one task at any one time. Single core = single task, a “quad core” CPU can run a maximum of 4 threads/tasks at any one time.
- Multitasking is when an operating system manages many programs being loaded at once in memory (multiprogramming) but also then allows the user run / use two or more of those applications at the same time.
- On a single core, multitasking gives applications the appearance of working at the same time – for example your music keeps playing when you switch to your web browser to find something on the web.
- Because each CPU core can only run one task at a time, the OS must manage the amount of time the CPU spends on each task and switch quickly between them to give the appearance of all tasks running simultaneously.
- This is the computing equivalent of spinning plates – you spend just enough time on each task to keep it going before switching to the next.
- The more cores a CPU has, the more “genuine” multitasking can be carried out – more cores mean more tasks actually do run in parallel.
- If there are too many tasks or the CPU is busy with one single task which has taken priority, the user may notice programs begin to “stutter” or not respond as it simply hasn’t got round to servicing that task.
- This means that multitasking is usually an “illusion” – the tasks are NOT all really being executed by the CPU all at the same time, most are waiting.
- Because CPU’s are so fast (gigahertz, remember?) they can do this task switching so quickly, we as users do not notice and we think tasks are all running simultaneously.
Peripheral Management and Drivers
Designing a modern operating system is a staggeringly complex task. One of the main reasons for this is the sheer quantity of things we can, and do, plug in to our computers. If you stop and think for a while, I’d be willing to bet you could easily write down a list of over 100 different devices that you can plug into a USB port alone. This creates something of a problem for operating systems engineers.
Remember that the purpose of an operating system is to control and manage all hardware and software in a computer system and to provide a platform for software to run on. The implication of this is that a user should reasonably expect to plug anything they like in to their computer and it “just works.” But how on earth do you design an operating system to be compatible with devices that don’t even exist yet? And surely an operating system cannot be programmed to know about every single device in existence at the point of release. This seems very unreasonable.
We are so used to things “just working” but this has absolutely not always been the case. Indeed, the reliable use of plug in devices has only really happened in the last 20 years or so (which seems a long time but isn’t) and has its roots back in 1995 when “plug and play” was a revolution. The idea that you could simply plug in a new graphics card or a scanner and the operating system would cleverly make it all work was nothing short of a miracle. Your average beardy computer historian will happily tell you their war stories about configuring a sound card for three days straight, reverse engineering the jumper configurations and working out IRQ clashes until the early hours…
The answer to most of these issues came in the form of extremely clever pieces of software called “drivers.” Let’s look more closely at this idea of managing peripheral devices.
Understanding the peripheral problem
Before we go any further, it would be sensible to define a couple of key terms:
Peripheral – any hardware device which provides input, output or other functionality which is plugged in to a computer system. It is not an essential component such as CPU, memory or storage.
Driver – software which controls and manages a hardware device. Acts as form of translation layer between the operating system and the hardware device itself.
 |
There are countless manufacturers of PC hardware and even if we were to focus on one type of hardware such as a graphics card, we still encounter problems. Whilst all graphics cards perform the same task – producing images, the way in which each card does this task is different. Manufacturers all invent their own proprietary methods of tackling a problem and this requires significant investment. They are not going to openly share their secrets as this is what gives their products value and gives a competitive edge in the market place.
Operating systems engineers came up with a superb solution to this problem. Operating systems provide a standardised platform for hardware and software. What this means is…
- The operating system will provide a set of fixed, standardised features and functions
- These functions are clearly documented so anyone may make use of them
- These functions rarely, if ever, change in any way – meaning upgrades, updates and time passing make no difference as things will just keep working
- The operating system will take care of any communication or interaction with other hardware devices that may need to take place
- Hardware manufacturers know they must make products which conform or interact with these standards if they want their hardware to work
- Software developers know exactly which functions they have access to, and which they must make/provide for themselves.
A standard is nothing more than a clearly defined and published method of doing something. One example in an Operating System might be drawing a window on screen or handling text input from the keyboard. A programmer will know that if they want a user to type something in, then the operating system will have a built in function they can use and they simply call this rather than writing their own code to do the same thing. This is great news for developers because its less work for them.
Standards usually lead to systems, programs and hardware being much more reliable – built in operating system functions will have been endlessly and rigorously tested. In comparison, code we write ourselves often works, but then is broken in the real world when users do things we never expected them to do.
The same is true for hardware manufacturers. For example, if HP wish to make a new printer and it must work with Windows, then they know exactly how Windows will provide the page to be printed. Exactly how HP decide to transfer that binary stream of data into a physical page of text and images is entirely up to them – Microsoft don’t care! They have provided data in a standard format, the rest is up to the hardware designers and this is where drivers come in.
Drivers
You should now be clear that an operating system works by implementing standards – fixed, well defined methods of carrying out tasks. The operating system will allow any device to communicate with it if that device sends and receives data in the standard format defined by the operating system. Finally, the operating system does not care or know about what the hardware device does, it simply passes data off to the device and lets it get on with the job it is designed to do.
As we discovered earlier, hardware manufacturers all do things differently. Some design their own chips and controllers, others may buy off the shelf components and use those. All manufacturers can add and remove special features from their devices to entice customers to buy them. Due to these differences, every hardware device must come with a software driver.
The job of a driver is to effectively translate the custom, proprietary signals or data that a device produces into the generic signals and messages that an operating system expects. Drivers are software that sit between the kernel of an operating system (the bit which manages all hardware) and the device itself. Without a driver, the operating system would not understand how the device worked and the device would not be able to communicate with the operating system.
Every device, regardless of how simple – even a keyboard, must have a driver. Manufacturers are responsible for producing the drivers for devices simply because they are the ones who know how it works! This is a good thing for manufacturers because it enables them to “upgrade” a device just by adding new functions in to the software and then updating the driver to deal with these functions.
However, as with everything in computing, there is a compromise. Manufacturers may do a poor job of writing and maintaining their drivers. If they do this, devices can be unstable, they may never recieve updates to fix bugs and ultimately this lack of support by manufacturers is how some devices end up being e-waste when they would otherwise be perfectly usable with updated software support.
The advantages of drivers are numerous:
- The OS does not need to know about every piece of hardware in existence, this makes the OS easier to manage and much smaller than it would otherwise be.
- The OS only needs to have software/drivers for the specific hardware connected to it.
- Drivers enable OS’s to run/use hardware that is new or newer than the operating system – this is how come an OS can run hardware that wasn’t even known about at launch.
- Drivers enable new features, bug fixes etc to be quickly and easily applied to a piece of hardware without affecting the OS
User Management
When designing an operating system, there is an important choice to be made – will the system be used solely by one person who can access and use the entire of the available resources or, is it necessary to enable multiple users to access the system (potentially simultaneously) and to share the available resources?
In some cases, the choice that has been made is obvious. For example, an Android or iOS smart phone has almost certainly been designed as a single user operating system. A phone is a personal device, not meant to be shared with others and as such it makes sense that the OS would be optimised for only one user.
The computers you will use at school are a totally different scenario. Each of you has a set of credentials – a user name and password, which are unique to you and allow you to access any computer in any room. This is only possible due to the fact that Windows (in recent times) is a multi-user operating system.
But… there’s a catch. You knew it couldn’t be that simple, didn’t you?
When we refer to multi user operating systems, we have to be very careful because it can mean two different things:
- Multiple users can log in to a system, but only one may use the computer/resources at a time
- Multiple users can log in to a system and all use/share the resources at the same time
Your Windows desktop PC is an example of the first type of multi user operating system. It will allow anyone with the correct credentials to log in to the computer, but only one person may use that computer at any one time. That user also has sole use of all resources in that system.
Linux and Unix are examples of operating systems that were designed from the ground up to be true multi-user systems. In a Linux/Unix environment, multiple users may log in to the system at the same time and share the resources.
For clarity, this does not mean you plug 15 keyboards, mice and displays into a computer and all start working around a table. Multi-user operating systems are designed to be logged in to through some kind of terminal (another computer) which is usually remote (in another room/building/country). These kinds of operating system are most prevalent in server environments – large, powerful systems with lots of resources can be effectively shared amongst the many users that log into it.
To summarise:
- Single user systems
- Designed to be used by one person
- They have full access to all the resources of that machine.
- Not designed to share resources with other users / cannot be logged in to by other users
- Multi User
- Many people can log in to the SAME system at the same time
- Resources are shared amongst the users logged in
- Usually requires powerful hardware and is often conducted on “mainframes” or servers.
- The advantage of this is that it is easier to manage than lots of single user machines – it is easy to give everyone a consistent, similar experience.
- Another advantage is it can often be cheaper than providing single user systems for every user of a system.
- A disadvantage is that users may not have access to resource intensive software such as photo or video editing packages.
Levels of access
In any kind of managed environment such as a client – server network or a multi-user operating system, there is a need to assign different roles to certain users. For example, the person in charge of the network would need to be an “administrator” – someone who can change any settings they wish, install software, create new users and so forth. They have complete control over the system.
However, someone such as a student would only need permission to use the system and carry out their work. You would not want a student to be able to install software, delete shared files or create new users! For this reason, they would be given fewer “permissions” to control and regulate their access to the system.
This ability to assign permissions or “roles” to different users gives administrators a great deal of fine control over their system and massively enhances security. Permissions are the first step in securing a network so that users simply cannot perform malicious tasks or activities on the system!
Some examples of user roles are below:
User management may also include the management of rights and permissions that different users have, for example:
- Administrators – These users are able to do anything on a device. They have full control and can view, edit, create and delete content anywhere – including looking at other users’ accounts.
- Power Users – These users have some “elevated privileges.” For example they may be able to change user passwords or install their own software
- Standard User – These are the “normal” users on a system – like your user account at school. You have access to the resources and programs you need, but you cannot change settings or install/delete software.
- Restricted/Guest User – These accounts are designed to be “locked down” and provide only what is strictly necessary for these users. Think about exam accounts you may have used that did not allow you on the internet or school share, for example.
File management
One of the most important functions that an operating system carries out is the management of files, file storage and secondary storage devices.
A storage device is simply an extremely large container for binary bits, you can imagine it as the equivalent of a huge empty warehouse. This space can be organised in any number of ways. How and where files are stored is entirely up to the operating system designer and the “file system” they choose to implement.
File systems are extraordinarily important as they look after not only all of the programs we have installed, but also our files such as documents, photos, spreadsheets and so on. This is our most valuable data and therefore the reliability of any file system is of paramount importance. If an operating system developed a reputation for randomly losing your files, you wouldn’t use it for very long.
Each modern OS has its own unique file system which will have benefits and drawbacks specific to the chosen design. There are also file systems designed for specific tasks such as network attached storage (NAS) drives and server environments where many hundreds of disks / solid state drives may be managed as one large storage area.
All operating systems need to offer a simple, user friendly method for users to access, manage and manipulate files. In Windows, since 1995, this has been called “File Explorer” and in MacOS it has nearly always been “Finder.” Both perform almost identical tasks.
Whether using Windows, MacOS, Linux or any other operating system, the file management facilities will be identical. Any file manager needs to allow users to (this is the bit to remember for the exam)
- Create new folders
- Move files between folders
- Cut, Copy, Paste files or folders
- Delete files or folders
- Rename files or folders
File managers often provide far more functionality than these basic requirements such as previews of files and the ability to connect to different drives, but for our exam this is enough.
To summarise:
- An operating system should manage the way files are stored on a computer, the way it does this is called the file system.
- Some examples of file systems are AppleFS, Fat32, NTFS and EXT4. Each one organises secondary storage in a different way.
- A file system will manage the storage, retrieval and deletion of files on a device.
- File systems must be incredibly robust – they must handle:
- Read or write errors without losing data
- Ensuring no files or data are lost or over written
- Redundancy – making it so if one copy of data is lost then there is another copy (RAID does this, fly bravely to Wikipedia, my friends)
- Quick access to files and data
- Managing storage efficiently so the user/OS can make maximum use of the space available